18장, UPack PE 헤더 상세 분석

UPack으로 압축한 notepad를 PEView로 열었을 때, PE HEADER를 제대로 읽어들이지 못한다. IMAGE_OPTIONAL_HEADER, IMAGE_SECTION_HEADER 등의 정보들이 없다.
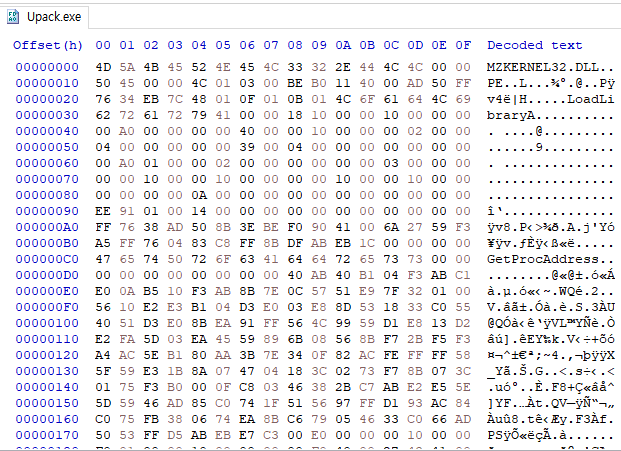
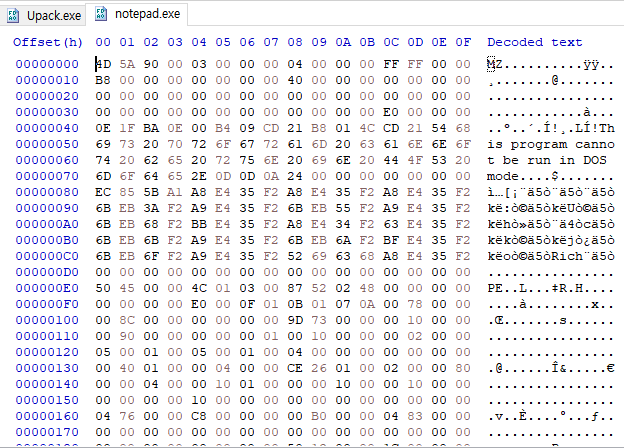
HxD로 notepad와 Upack을 살펴보니 차이점이 뚜렸하다. 먼저 MZ 뒤에 써있는 KERNEL32.DLL
MZ와 PE 시그니처간의 간격이 너무 가깝기도 하다. DOS Stub 영역이 없어서 그런 것 같다.
18.5. UPack의 PE 헤더 분석
18.5.1 헤더 겹쳐쓰기
IMAGE_DOS_HEADER와 IMAGE_NT_HEADERS를 겹쳐쓰는 기법이다. 헤더를 겹처씀으로서 헤더 공간을 절약할 수 있으며 복잡성을 증가시켜 분석을 어렵게 만든다. Stub_PE로 IMAGE_DOS_HEADER(MZ 헤더)를 살펴본다.
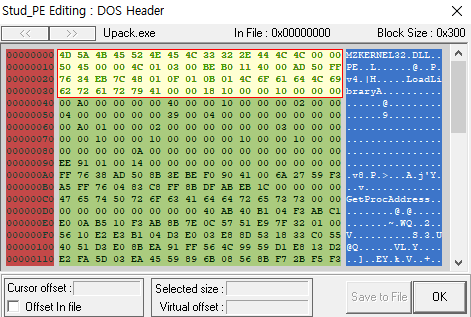
MZ 헤더에서 중요한 멤버는 e_magic과 e_Ifanew이다. 그 외 나머지는 프로그램 실행에 영향이 없는 멤버들이다. e_Ifanew의 값에 따라서 IMAGE_NT_HEADERS의 시작 위치가 결정된다.
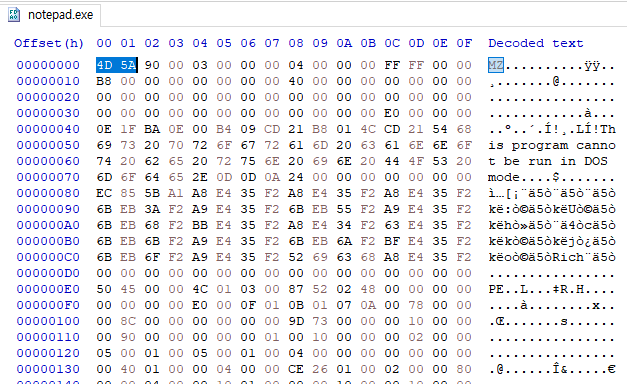
정상적인 notepad에서는 000000F8이었던 e_Ifanew 값이 00000010이 되었다. 이를 통해 IMAGE_DOS_HEADER와 IMAGE_NT_HEADERS가 겹쳐있다는 것을 알 수 있다. PE 스펙 자체는 갖추고 있다.
18.5.2. IMAGE_FILE_HEADER.SizeOfOptionalHeader
IMAGE_FILE_HEADER.SizeOfOptionalHeader의 값을 변경하면서 헤더 안에 디코딩 코드를 삽입한다. 값의 의미는 PE 헤더에서 바로 뒤따르는 IMAGE_OPTIONAL_HEADER 구조체의 크기(E0)이다. UPack은 이 값을 148로 변경했다.
IMAGE_OPTIONAL_HEADER는 구조체이기 때문에 이미 PE File format에서 그 크기가 E0로 정해져 있다. 원래 의도는 PE 파일의 형태에 따라서 각각 IMAGE_OPTIONAL_HEADER 형태의 구조체를 바꿔 끼울 수 있도록 설계했다.
또한, SizeOfOptionalHeader의 또 다른 존재의의는 IMAGE_SECTION_HEADER의 시작 offset을 결정하는 역할이다. PE 헤더를 보면 IMAGE_OPTIONAL_HEADER에 이어서 IMAGE_SECTION_HEADER가 나타나는 것처럼 보인다. 하지만 실제로는 IMAGE_OPTIONAL_HEADER의 시작 offset에 SizeOfOptionalHeader 값을 더한 위치에서부터 IMAGE_SECTION_HEADER가 시작되는 방식이다.
UPack에서는 IMAGE_OPTIONAL_HEADER 시작 offset 28 + SizeOfOptionalHeader(148)=170에서IMAGE_SECTION_HEADER가 시작한다.
UPack이 이렇게 값을 변경하는 이유가 무엇일까? UPack의 특징은 Pㄸ 헤더를 뒤섞어놓고 헤더 안에 디코딩에 필요한 코드를 적절히 끼워 넣는 것이다. SizeOfOptionalHeader 값을 늘리면 IMAGE_OPTIONAL_HEADER와 IMAGE_SECTION_HEADER 사이에 공간을 확보할 수 있고, 이 영역에 디코딩 코드를 충가한다.
다시 예시를 보면, IMAEG_OPTIONAL_HEADER의 끝은 D7이고 IMAGE_SECTION_HEADER의 시작은 170이다. 이 사이 영역을 HexD로 확인한다.
원본 notepad.exe에서 섹션헤더의 시작위치는 1D8이지만 notepad_upack.exe는 170에서 시작한다. StudPE로 notepad_upack.exe를 확인해보면, DATA_DIRECTORY가 끝나는 108부터 IMAGE_SECTION_HEADER가 시작하는 170까지 68만큼의 공간이 생겼다.

이 영역은 PE헤더 정보가 아니라 UPack에서 사용하는 디코딩 코드이다. 만약 PE 관련 유틸리티가 이 부분을 PE헤더 정보라고 판단하면 오동작을 일으킨다.
18.5.3. IMAGE_OPTIONAL_HEADER.NumberOfRvaAndSizes
이 값의 변경 역시 Upack이 자신의 코드를 사용하기 위한 이유이다. NumberOfRvaAndSizes는 바로 뒤에 이어지는 IMAGE_DATA_DIRECTORY 구조체 배열의 원소 개수를 나타낸다. 정상적인 파일에서 IMAGE_DATA_DIRECTORY 배열의 원소 개수는 10(16개)이지만, UPack에서는 A(10개)로 변경된다.
IMAGE_DATA_DIRECTORY 구조체 배열의 원소 개수는 이미 10으로 정해져 있지만, PE 스펙에 따르면 NumberOfRvaAndSizes 값을 배열의 원소 개수로 이정하도록 되어 있다. 앞선 SizeOfOptionalHeader와 같은 개념이다. 따라서 UPack의 경우 IMAGE_DATA_DIRECTORY 구조체 배열의 마지막 6개 원소는 무시한다.
그리고 그 무시된 영역에 자신의 코드를 덮어씌운다. 여기서 마지막 6개 배열 중 가장 앞의 주소가 바로 D8이다.
18.5.4. IMAGE_SECTION_HEADER
IMAGE_SECTION_HEADER 내에서 프로그램 실행에 사용되지 않는 멤버들에 UPack의 데이터를 기록한다. 이 기법 역시 앞선 방법과 같은 맥락이다.
위에서 확인한 바로 NumberOfSections의 값은 3이었고, IMAGE_SECTION_HEADER는 170에서 시작한다.
PE File format에서 IMAGE_SECTION_HEADER 구조체의 크기는 28hex 였으므로, 이 구조체 3개는 78hex.
170(hex)+78(hex)=1E8. 즉, 170~1E7 범위가 IMAGE_SECTION_HEADER의 영역이다.
18.5.5. 섹션 겹쳐쓰기
첫 번째 섹션과 세 번째 섹션의 파일 시작 offset(RawOffset) 값이 10으로 같다. offset 10은 헤더 영역인데 Upack에서는 이곳에서 섹션이 시작된다.
첫 번째 섹션과 세 번째 섹션의 크기도 같다. 단, 섹션의 메모리 시작 offset(RVA)와 메모리 크기(VirtualSize)값은 다르다.
결론. UPack은 PE헤더, 첫번째 섹션, 세번째 섹션이 겹쳐 있는 상태이다. PE로더는 파일 offset 0~1FF 영역을 3곳의 서로 다른 메모리 위치에 매핑한다. 같은 파일 이미지를 가지고 각기 다른 위치와 다른 크기의 메모리 이미지를 만들 수 있다.
'파일'의 첫 번째 섹션의 크기는 200으로 다소 작은 편이지만 두 번째 섹션의 크기는 파일의 대부분을 차지할 정도로 크다.
'메모리'의 첫 번째 섹션 크기는 14000이다. 이 값은 원본 파일의 SizeOfImage 값과 같다. UPack의 두 번째 섹션 안에, 원본 파일의 압축된 이미지를 저장해두었다가, UPack의 첫 번째 섹션에 풀어주는 것이다.
18.5.6. RVA to RAW
각종 PE 유틸리티가 정상 동작하지 못한 이유는 RAV->RAW 변환에 어려움이 있었기 때문이다. UPack 제작자는 PE 로더의 버그(예외 처리) 를 알아낸 후 이를 UPack에 적용했다.
일반적인 RVA->RAW 변환 공식은 다음과 같았다.
| RAW = RVA - VirtualAddress + PointerToRawData |
위 공식대로 EP의 파일 offset(RAW)을 계산해보면, UPack의 RVA : 1018, RVA 1018은 첫 번째 섹션에 포함되고, fileoffset은 10이다.
(1018-1000+10 =28)

문자열이 저장되어 있다. 실제로 Ollydbg의 초기 버전은 이렇게 UPack의 EP를 찾아내지 못했다.
섹션 시작 파일의 Offset을 PointerToRawData 값은 FileAlignment의 배수가 되어야 한다. UPack의 FileAligment는 200임으로 200의 배수가 되어야 한다. 만약, PE로더가 보았을 때 PointerToRawData가 FileAlignment의 배수가 아니면 이를 200에 맞춰서 인식한다. 이 경우에는 0으로 인식한다. 이 때문에 UPack이 정상 실행은 되지만 PE 유틸리티에서 오류가 발생했던 이유다.
디버거로 해당 영역인 Imagebase+28을 따라가보면 코드를 확인할 수 있다.
18.5.7. Import Table(IMAGE_IMPORT_DESCRIPTOR array
HxD를 이용해서 IMAGE_IMPORT_DESCRIPTOR 구조체를 따라가본다. Directory Table에서 IMAGE_IMPORT_DESCRIPTOR 구조체 주소를 얻는다.
앞의 4바이트는 RVA, 뒤의 4바이트는 VirtualSize이다. 000271EE가 RVA이다. HeD로 보기 위해서는 RVA를 RAW로 바꿔 주어야 한다. 271EE는 세 번째 섹션에 속해 있다.
271EE - 27000 + 0(RawOffset이 10이 아니라 0으로 강제 변환된다) = 1EE

이제 HxD로 1EE offset을 확인하면 되는데 여기서 UPack의 트릭이 시작된다.
PE 스펙에 따르면 Import Table은 IMAGE_IMPOR_DESCRIPTOR 구조체 배열로 이루어지고 마지막 NULL 구조체로 끝나야 한다. 이 구조체의 크기는 14(hex)/20Bytes이다. 드래그 된 영역이 구조체배열의 첫 번째 앨리먼트인데, 그 뒤는 두 번째 구조체도 아니고 끝을 나타내는 NULL도 아니다.
앞서 세 번째 섹션의 영역은 0~1FF였다. HexD에서는 27000~271EE 범위인데, 이 세 번째 섹션의 끝이 바로 1FF이기 때문에 그 뒤에 잘린 부분은 세 번째 섹션에 매핑되지 못했다.
0~1FF 영역이 27000~271FF에 매핑되고, 나머지 27200~28000까지는 NULL로 채워진다. 때문에 위의 HexD 이미지도 200부터는 NULL로 채워진 것을 확인할 수 있다. 200~201도 첫 번째 구조체에 포함되어야 하기 때문에 원래 아마 다른 값이 있어야 했을 것이다.
디버거로 271EE~27201 을 확인해보면 27200까지 제대로 매핑되고 20202부터 NULL 구조체가 나타난 것으로 볼 수 있을 것이다. Import Table이 깨진 것 처럼 보이지만 사실은 Import Table이 정확하다는 트릭을 가지고 있다.
18.5.8. IAT(Import Address Table)
UPack이 어떤 DLL에서 어떤 API를 Import하는지 실제로 IAT를 따라가서 확인해본다.
| offset | member | RVA |
| 1EE | OriginalFirstThunk(INT) | 0 |
| 1FA | Name | 2 |
| 1FE | FirstThunk(IAT) | 11E8 |
Name의 RVA는 2이고, Header 영역에 속한다. 첫 번째 섹션이 1000이기 때문에 그 이전인 헤더영역이다.
헤더 영역에서는 RVA와 RAW값이 일치하므로 offset 2를 확인해보면

KERNEL32.DLL 을 확인할 수 있다. 이 위치는 DOS헤더에서 사용되지 않는 영역이기 때문에 UPack이 이곳에 Import DLL 이름을 써 두었다. 빈 공간에 데이터를 채우는 UPack의 특성이 여기서도 보인다. DLL 이름을 알았으니 어떤 API를 Import하고 있는지 확인해본다.
원래는 OriginalFirstThunk(INT)를 따라가보면 API 이름 문자열을 확인할 수 있지만 , UPack과 같이 INT 값이 0일 경우 IAT를 따라가본다. INT와 IAT 어느쪽에서든 문자열을 얻기만 하면 된다. 11E8은 첫 번째 섹션의 영역이므로 이를 RVA->RAW 변환 해 보면 1E8이다.

역시 쉽게 나타나지 않는다. 표시된 영역은 IAT이면서 INT역할을 동시에 하고 있다. 이 위치는 즉 Name Pointer 배열이고 배열의 끝은 NULL이다. 다른 값은 보기 힘들고 BE와 28이라는 값만 보인다. 이 위치를 확인해본다.


'Reversing > 리버싱 핵심 원리' 카테고리의 다른 글
| [리버싱 핵심 원리] 21장, Windows 메시지 후킹 (0) | 2021.11.24 |
|---|---|
| [리버싱 핵심 원리] 19장, UPack 디버깅 - OEP 찾기 (0) | 2020.11.19 |
| [리버싱 핵심 원리] 17장, 실행 파일에서 .reloc 섹션 제거하기 (0) | 2020.11.15 |
| [리버싱 핵심 원리] 16장, Base Relocation Table (0) | 2020.11.07 |
| [리버싱 핵심 원리] 5장, 스택(Stack) (0) | 2020.11.07 |



